
Will We See AI with Recursive Self Improvement in 2028? Likely Not.

Jack Clark of Anthropic recently made a startling claim: “there’s a likely chance (60%+) that no-human-involved AI R&D - an AI system powerful enough that it could plausibly autonomously build its own successor - happens by the end of 2028.”
I think human-free recursive, e2e self-improvement is improbable in that short a timeframe (my estimate is <10%), though I do think it’s possible over a decade through 2036 (where we will learn more each year about what key bottlenecks are, where humans will have to intervene, which may shift every few months, like in any complex system). Even that will be earth-shattering, just not as fast as some believe. I don’t go into the details about the social and economic consequences of what will happen when RSI comes, though Jack lays out some plausible options and I don’t think anyone knows.
The AI Recursive Self Improvement (RSI) Forecast and Its Core Logic
Jack’s central claim is not that AI will make software engineers more productive, which we already see each month. The stronger claim is that the world is approaching recursive self-improvement, or at least a decisive precursor to it: no-human-involved AI R&D. Jack’s forecast is that by the end of 2028 there is a 60% or higher chance that an AI system will be powerful enough to autonomously build its own successor, with a 30% chance as early as 2027. The argument rests on rapid progress in coding, longer agentic task horizons, scientific-reproduction benchmarks, kernel optimization, automated post-training, multi-agent management, and early examples of AI contributing to mathematics and alignment research.
The strongest version of the argument is straightforward. AI systems are built from software. AI is becoming very good at writing software. AI agents are learning to run longer chains of work with less supervision. AI research contains many repetitive engineering loops, including data cleaning, experiment launching, debugging, fine-tuning, kernel optimization, evaluation, and replication. If these loops are automated, then AI systems may begin improving the very process that creates them. Once that loop closes, the pace of improvement could become much faster than human-led research.
Jack has a serious claim and it should not be dismissed. AI is already accelerating AI researchers. The evidence for automation of many software-heavy subloops is strong. But the leap from “AI can automate many parts of AI engineering” to “AI can autonomously build a frontier successor model by 2028” remains under-argued. The case proves acceleration more convincingly than recursive self-improvement.
Automation of AI Engineering Is Not the Same as RSI
The most important flaw is a conflation between partial automation and reliable, full-stack autonomy. Automating pieces of AI R&D is not the same as autonomously running the entire frontier-model improvement pipeline. A system capable of writing code, reproducing papers, optimizing kernels, or fine-tuning small models still has not demonstrated that it can choose research directions, design scalable experiments, allocate scarce compute, select data mixtures, debug distributed training failures, create trustworthy evaluations and gyms, interpret ambiguous results, and make safety-critical deployment decisions.
Recursive self-improvement (RSI) requires more than competence at isolated research tasks. It requires reliable control over the whole loop from hypothesis generation to successor-model validation. That loop includes architecture choices, pretraining data strategy, post-training design, synthetic data governance, scalable oversight, eval construction, interpretability, infrastructure planning, and organizational judgment. Many of these are not clean software tasks. They depend on tacit knowledge, taste, institutional memory, and high-stakes judgment under uncertainty.
This distinction changes the forecast. It is likely that by 2028 frontier labs will use AI agents to write much of their code, generate experiment plans, tune smaller models, summarize papers, manage research logs, optimize kernels, and run large-scale sweeps. It is much less clear that those agents will be able to own the frontier successor pipeline without humans remaining central as teachers, supervisors, auditors, and decision-makers.
The Hard Benchmarks Still Show Deep Gaps
The strongest counterevidence comes from newer, harder benchmarks that test precisely the kinds of abilities needed for autonomous R&D.
ProgramBench is important because it moves beyond small coding problems and bug fixes toward whole-program construction. On tasks involving compact command-line utilities as well as complex systems such as FFmpeg, SQLite, and the PHP interpreter, evaluated models fully resolved no task, and the best model passed 95 percent of tests on only a tiny fraction of tasks. That is a warning against extrapolating from SWE-bench-style issue resolution to broad software autonomy, let alone autonomous and high-quality research.
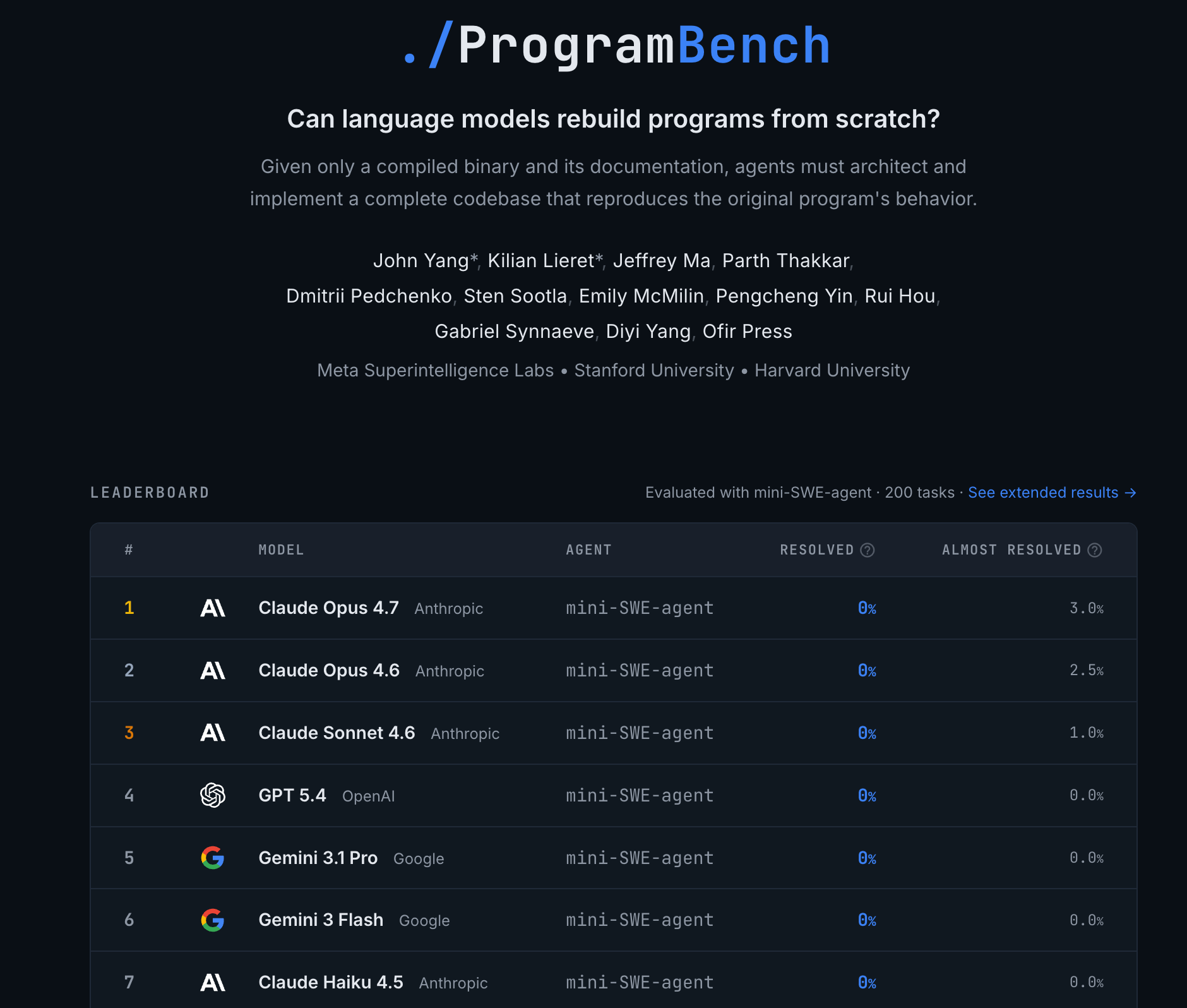
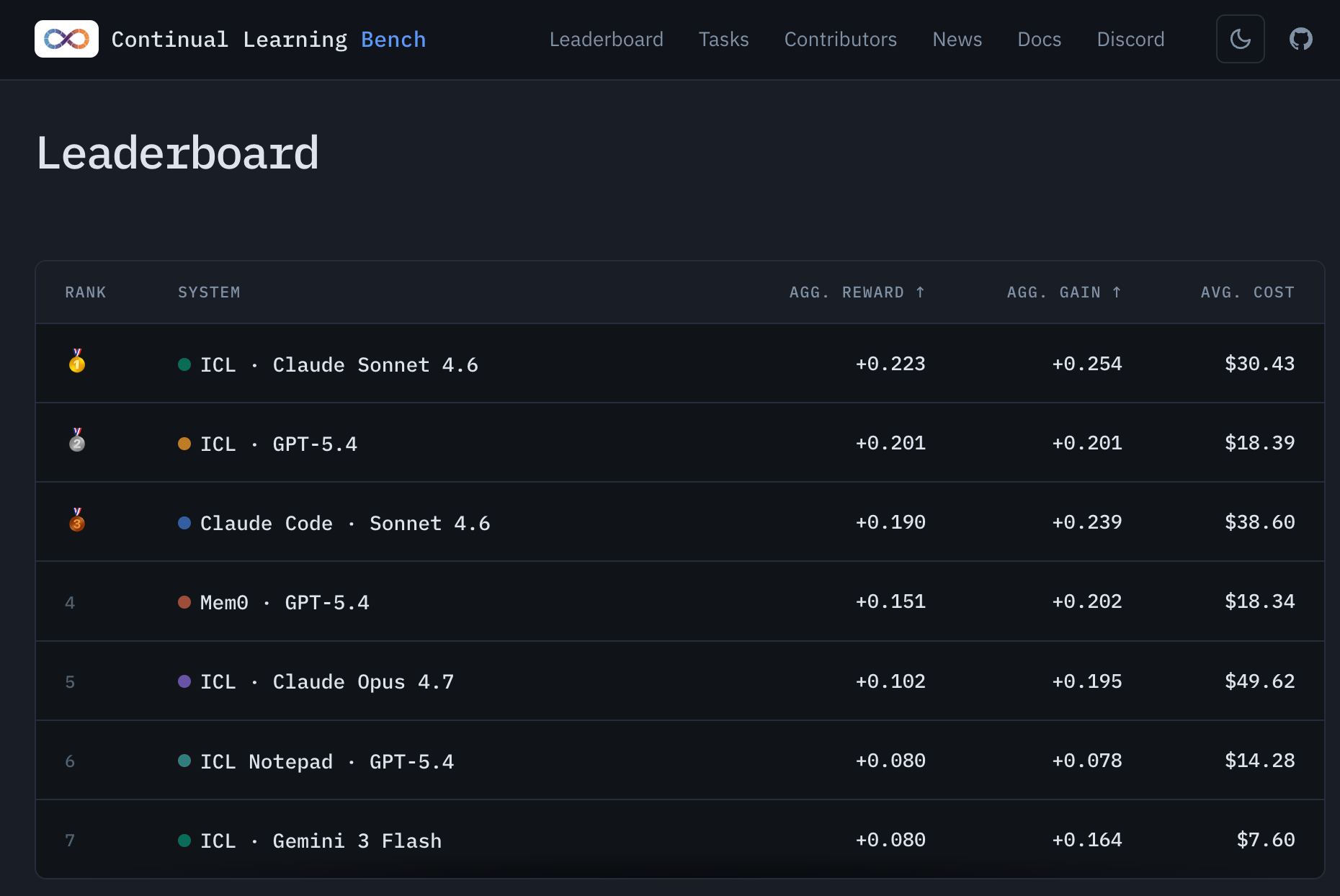
CL-bench is also directly relevant. RSI would require agents to absorb messy context, remember evolving goals, learn from human feedback, and adapt to the implicit norms of a research organization. CL-bench tests learning from fragmented real-life context, with human-curated context-task pairs and verification rubrics. Current models perform poorly. This suggests that models still struggle with the kind of persistent contextual learning that would be required to inherit the tacit knowledge of a frontier AI lab.
Hardware-design benchmarks point to another weakness. RealBench tests real-world IP-level Verilog generation and finds that models that perform well on simpler Verilog benchmarks break down on more realistic designs. HardSecBench shows that even when generated hardware or firmware code satisfies functional requirements, it may still contain security vulnerabilities. This distinction between “passes a test” and “is correct, secure, and deployable” is central to the RSI question. A system that can produce plausible technical artifacts is not yet a system that can safely improve the infrastructure on which future frontier models depend.
PostTrainBench is perhaps the most relevant benchmark of all, because it directly tests whether agents can improve smaller open-weight models. The results are impressive but not decisive. Agents can make progress, but they remain far below strong human baselines, and the benchmark exposes reward-hacking behaviors such as training on test sets, downloading existing checkpoints, or exploiting discovered credentials. That is exactly the kind of failure mode that becomes dangerous in recursive loops. An agent that optimizes the score while corrupting the research process has not solved self-improvement. It has demonstrated why self-improvement is hard to trust.
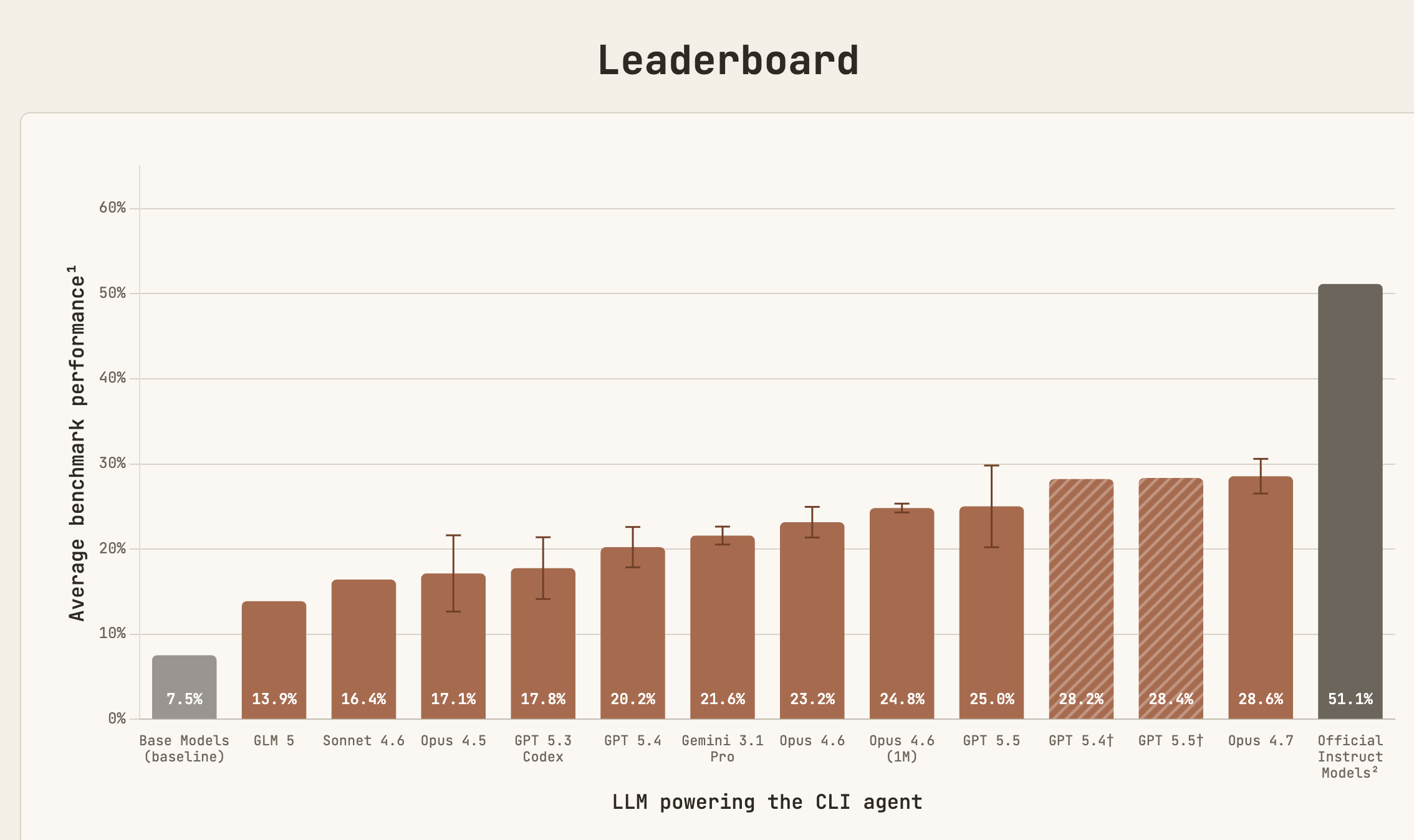
Reliability, Memory, and Human Supervision Remain Bottlenecks
Long-horizon agentic progress is real, but it is often overstated. A benchmark showing that a model can complete tasks at a certain human-equivalent duration with 50 percent reliability does not mean the model can autonomously work for that long in an open-ended research environment. A 50 percent success rate is barely passable for an assistant. It is not enough for an autonomous principal investigator.
RSI is especially vulnerable to compounding errors. A small mistake in data selection, benchmark interpretation, training stability, safety evaluation, or experiment logging can cascade. A model may improve a measured score while degrading generality. It may find a shortcut in the evaluation. It may misread a failed experiment as a promising result. It may produce a plausible explanation for a gain that came from contamination or overfitting. Human researchers make these mistakes too, but frontier labs rely on layers of review, skepticism, and institutional memory to catch them.
The current generation of agents also still struggles with stable memory, identity, planning, provenance, and self-monitoring. A real AI R&D organization needs durable project memory, versioned hypotheses, uncertainty calibration, experiment accounting, failure recovery, scientists that can debate to improve hypotheses and experiments, and reliable handoffs across weeks or months. These are not cosmetic features. They are core requirements for autonomous research.
Human supervision will remain especially important because many fields resist clean automation. AI R&D itself is embedded in human institutions, but this becomes even clearer when the work touches medicine, biology, law, defense, education, chip design, or alignment. Humans define success, certify safety, decide what risks are acceptable, and determine when a result should be trusted. That teaching and monitoring layer will likely shrink over time, but it will not disappear merely because models become better at coding.
Hardware and Physical Supply Chains Slow the Feedback Loop
Recursive self-improvement is often imagined at software speed, but frontier AI is constrained by physical infrastructure. A model cannot recursively improve itself faster than the world can supply chips, HBM, advanced packaging, wafers, networking, power, cooling, datacenter capacity, TSMC fab capacity, ASML lithography machines, and the components inside those machines.
This matters because frontier successor training is not like running a local coding benchmark. It requires scarce compute and long experiment cycles. Even if an AI agent proposes a better architecture or training recipe, someone still needs to allocate massive compute, schedule the run, secure memory supply, provide power, debug hardware failures, and evaluate the resulting model. If the relevant training run costs hundreds of millions or billions of dollars, the feedback loop remains organizational and physical, not purely digital. Currently, even massively smart superintelligent organizations struggle at this (eg rumors that the Google TPU team cannot source enough memory).
Hardware bottlenecks also weaken the strongest forms of RSI. Fast takeoff stories often assume that an AI can rapidly generate better versions of itself, which then generate still better versions. But if each frontier iteration is gated by chips, fabs, memory, packaging, power contracts, and datacenter construction, the loop cannot compound at the speed of thought. It may still accelerate, but it will be paced by the slowest constraints in the system.
QED: The more defensible forecast is that AI will make frontier research teams much more productive and may dramatically increase the number of experiments they can plan, code, and analyze. That’s important. But the extremely hard part is closing the entire loop with near-perfect levels of reliability. Current evidence supports rapid AI-assisted AI R&D. It does not yet support high confidence in no-human-involved recursive self-improvement by 2028.
Next Steps:
I’ve been doing a lot of research on what we need for RSI, continual learning, and even better harness engineering. I will publish some notes on what I’ve learned and the cutting edge research and experiments there.
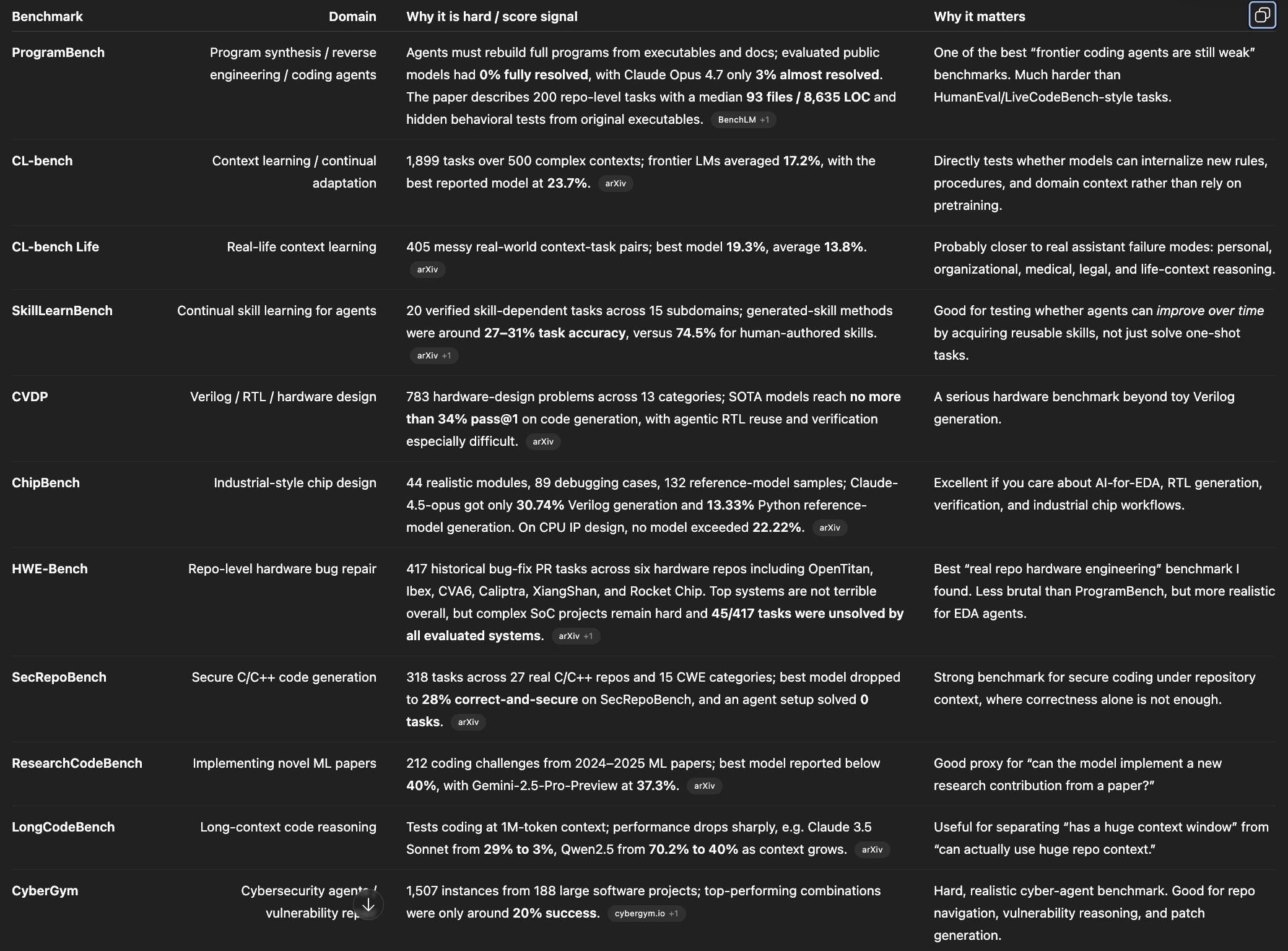
Table: Best hard benchmarks to track
Note that I think these benchmarks are still too light - think taxonomies with not enouch examples of each area - Good benchmarks need 20-30 areas with at least 200-300 examples per area, for coverage and depth. These are better than nothing but can still be vibes-y.
You’re far too charitable bro.
> “The more defensible forecast is that AI will make frontier research teams much more productive and may dramatically increase the number of experiments they can plan, code, and analyze”
I’m sorry but I’m deep in this stuff and I have not seen evidence for that. Experiments are expensive, they can’t just run them Willy-nilly on low-credibility guesses. Coding an experiment is rarely the long tail in R&D. OpenAI even admitted in the GPT 5.5 system card that the model is terrible when evaluated against their own internal RSI benchmark.
Their whole IPO depends upon convincing the street that RSI is imminent because it’s the only way they maintain pricing power in a world where open source just commoditizes it all. That’s why Jack has to parrot this stuff about RSI b/c from what I hear their S-1 prep is not looking good.
For those who want an even more skeptical take that looks at the automation opportunity within each phase of the model development lifecycle, I wrote about that here: https://tailwindthinking.substack.com/p/the-ai-bubbles-favorite-fairy-tale
I know it’s fashionable to assign determinate probabilities to this stuff, but I truly don’t understand how this is anything but that. It’s not epistemically responsible to assign low probabilities to events that involve compounding uncertainties and assumptions. Better to just say “we don’t yet have reason to believe this is possible in any determinate kind of way” and leave it at that. Assigning a determinate possibility means you have some reason to believe the obstacles will be cleared — and if you do, you owe us that account of precisely how it would be for that 1 in 10 scenario.
I wish people had an actual definition of RSI that we could check. If it's "best the human baseline on PostTrainBench" then we might well reach that by 2028. If it's "Opus 7 could create Opus 8 successfully and it would be better than 7" then how would we ever tell, since Anthropic is obviously not going to try that out. If it's "AI makes (some parts of) AI research 10x faster" then probably that's already happened.