Self-Supervised Learning: A Gentle Introduction
Next Frontiers in Machine Learning

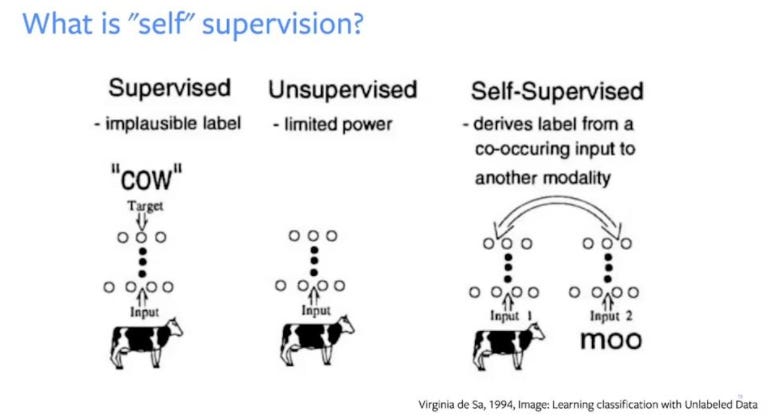
1. Overview of Self Supervised Learning (SSL) / SSL Basics
Self-supervised learning, also known as self-supervision, is an emerging solution to a common ML problem of needs lots of human-annotated data. In my opinion, it’s one of the next big breakthroughs in large-scale machine learning and I see it dominating the production-grade models that Google, Meta, OpenAI, and Microsoft (“the AI superpowers”) are quietly releasing.
In SSL, data labeling is automated, and human interaction is eliminated as a bottleneck, so we can scale from datasets of thousands or tens of thousands of examples to billions and really use the power of large-scale ML training clusters (which are basically supercomputers). In self-supervised learning, the learning model trains itself by leveraging one part of the data to predict the other part and generate labels accurately. In the end, this learning method converts an unsupervised learning problem into a supervised one. My teams working on SOTA ML problems see it as one of the generalized ways to get beyond the supervised approaches that deep neural networks use today, and see huge performance increases for tasks like content recommendation, medical diagnosis, level 5 AVs, virtual assistants interactions, etc.
» Longer post explaining SSL